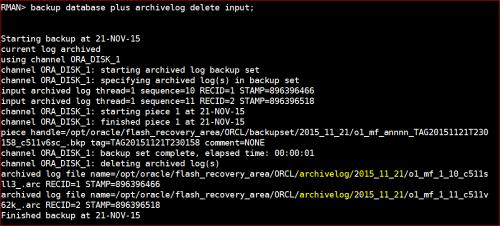
包含:检查Oracle实例状态,检查Oracle服务进程,检查Oracle监听进程,共三个部分。
1.1 检查Oracle实例状态
select instance_name,host_name,startup_time,status,database_status from gv$instance;
其中“STATUS”表示Oracle当前的实例状态,必须为“OPEN”;“DATABASE_STATUS”表示Oracle当前数据库的状态,必须为“ACTIVE”。
1.2 检查Oracle在线日志状态
col MEMBER format a50
select group#,status,type,member from v$logfile;
输出结果应该有3条以上(包含3条)记录,“STATUS”应该为非“INVALID”,非“DELETED”。注:“STATUS”显示为空表示正常。
1.3 检查Oracle表空间的状态
select tablespace_name,status from dba_tablespaces;
输出结果中STATUS应该都为ONLINE。
1.4 检查Oracle所有数据文件状态
col name format a80
select name,status from v$datafile;
输出结果中“STATUS”应该都为“ONLINE”。或者:
col file_name format a80
select file_name,status from dba_data_files;
输出结果中“STATUS”应该都为“AVAILABLE”。
1.5 检查无效对象
select owner,object_name,object_type from dba_objects where status!='VALID' and owner!='SYS' and owner!='SYSTEM';
如果有记录返回,则说明存在无效对象。若这些对象与应用相关,那么需要重新编译生成这个对象,或者:
SELECT owner, object_name, object_type FROM dba_objects WHERE status= 'INVALID';
1.6 检查所有回滚段状态
select segment_name,status from dba_rollback_segs;
输出结果中所有回滚段的“STATUS”应该为“ONLINE”。
1.7 查看归档日志产生频率
查看最近按天的归档日志产生频率
select trunc(completion_time) as ARC_DATE,
count(*) as COUNT,
round((sum(blocks * block_size) / 1024 / 1024), 2) as ARC_MB
from v$archived_log group by trunc(completion_time)
order by trunc(completion_time);
查看最近按天和小时区分的频率
SELECT
SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5) Day,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'00',1,0)) H00,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'01',1,0)) H01,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'02',1,0)) H02,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'03',1,0)) H03,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'04',1,0)) H04,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'05',1,0)) H05,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'06',1,0)) H06,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'07',1,0)) H07,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'08',1,0)) H08,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'09',1,0)) H09,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'10',1,0)) H10,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'11',1,0)) H11,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'12',1,0)) H12,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'13',1,0)) H13,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'14',1,0)) H14,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'15',1,0)) H15,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'16',1,0)) H16,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'17',1,0)) H17,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'18',1,0)) H18,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'19',1,0)) H19,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'20',1,0)) H20,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'21',1,0)) H21,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'22',1,0)) H22,
SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'23',1,0)) H23,
COUNT(*) TOTAL FROM v$log_history a
WHERE first_time>=to_char(sysdate-20)
GROUP BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5)
ORDER BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5) DESC;
2. 检查Oracle相关资源的使用情况
包含:
a.检查Oracle初始化文件中相关的参数值
b.检查数据库连接情况,检查系统磁盘空间
c.检查Oracle各个表空间使用情况,检查一些扩展异常的对象,
d.检查system表空间内的内容,检查对象的下一扩展与表空间的最大扩展值,总共七个部分。
2.1 检查Oracle初始化文件中相关参数值
select resource_name,max_utilization,initial_allocation, limit_value from v$resource_limit;
2.2 检查数据库连接情况
查看当前会话连接数,是否属于正常范围。
select count(*) from v$session;
select sid,serial#,username,program,machine,status from v$session;
其中:SID 会话(session)的ID号;
SERIAL# 会话的序列号,和SID一起用来唯一标识一个会话;
USERNAME 建立该会话的用户名;
PROGRAM 这个会话是用什么工具连接到数据库的;
STATUS 当前这个会话的状态,ACTIVE表示会话正在执行某些任务,INACTIVE表示当前会话没有执行任何操作;
如果建立了过多的连接,会消耗数据库的资源,同时,对一些“挂死”的连接可能需要手工进行清理。如果DBA要手工断开某个会话,则执行:
(一般不建议使用这种方式去杀掉数据库的连接,这样有时候session不会断开。容易引起死连接。建议通过sid查到操作系统的spid,使用ps –ef|grep spidno的方式确认spid不是ORACLE的后台进程。使用操作系统的kill -9命令杀掉连接)
alter system kill session 'SID,SERIAL#';
注意:上例中SID为1到10(USERNAME列为空)的会话,是Oracle的后台进程,不要对这些会话进行任何操作。
2.3 检查系统磁盘空间
如果文件系统的剩余空间过小或增长较快,需对其进行确认并删除不用的文件以释放空间。
df -h
2.4 检查表空间使用情况
#简单查询
select f.tablespace_name, a.total,f.free,round((f.free / a.total) * 100) "% Free"
from (select tablespace_name, sum(bytes / (1024 * 1024)) total
from dba_data_files group by tablespace_name) a,
(select tablespace_name, round(sum(bytes / (1024 * 1024))) free
from dba_free_space group by tablespace_name) f
WHERE a.tablespace_name = f.tablespace_name(+) order by "% Free";
#详细情况查询
SELECT DF.TABLESPACE_NAME, COUNT(*) DATAFILE_COUNT,
ROUND(SUM(DF.BYTES) / 1048576 / 1024, 2) SIZE_GB,
ROUND(SUM(FREE.BYTES) / 1048576 / 1024, 2) FREE_GB,
ROUND(SUM(DF.BYTES) / 1048576 / 1024 - SUM(FREE.BYTES) / 1048576 / 1024, 2) USED_GB,
ROUND(MAX(FREE.MAXBYTES) / 1048576 / 1024, 2) MAXFREE,
100 - ROUND(100.0 * SUM(FREE.BYTES) / SUM(DF.BYTES), 2) PCT_USED,
ROUND(100.0 * SUM(FREE.BYTES) / SUM(DF.BYTES), 2) PCT_FREE
FROM DBA_DATA_FILES DF,
(SELECT TABLESPACE_NAME,
FILE_ID,
SUM(BYTES) BYTES,
MAX(BYTES) MAXBYTES
FROM DBA_FREE_SPACE
WHERE BYTES > 1024 * 1024
GROUP BY TABLESPACE_NAME, FILE_ID) FREE
WHERE DF.TABLESPACE_NAME = FREE.TABLESPACE_NAME(+)
AND DF.FILE_ID = FREE.FILE_ID(+)
GROUP BY DF.TABLESPACE_NAME ORDER BY 8;
如果空闲率%Free小于10%以上(包含10%),则注意要增加数据文件来扩展表空间而不要是用数据文件的自动扩展功能。请不要对表空间增加过多的数据文件,增加数据文件的原则是每个数据文件大小为2G或者4G,自动扩展的最大限制在8G。
2.5 检查一些扩展异常的对象
select Segment_Name,Segment_Type, TableSpace_Name, (Extents / Max_extents) * 100 Percent From sys.DBA_Segments Where Max_Extents != 0and (Extents / Max_extents) * 100 >= 95 order By Percent;
如果有记录返回,则这些对象的扩展已经快达到它定义时的最大扩展值。对于这些对象要修改它的存储结构参数。
2.6 检查system表空间内的内容
select distinct (owner) from dba_tables where tablespace_name = 'SYSTEM' and owner != 'SYS' and owner != 'SYSTEM' union select distinct (owner) from dba_indexes where tablespace_name = 'SYSTEM' and owner != 'SYS' and owner != 'SYSTEM';
如果记录返回,则表明system表空间内存在一些非system和sys用户的对象。应该进一步检查这些对象是否与我们应用相关。如果相关请把这些对象移到非System表空间,同时应该检查这些对象属主的缺省表空间值。
2.7 检查对象的下一扩展与表空间的最大扩展值
select a.table_name, a.next_extent, a.tablespace_name from all_tables a, (select tablespace_name, max(bytes) as big_chunk from dba_free_space group by tablespace_name) f where f.tablespace_name = a.tablespace_name and a.next_extent > f.big_chunk union select a.index_name, a.next_extent, a.tablespace_name from all_indexes a, (select tablespace_name, max(bytes) as big_chunk from dba_free_space group by tablespace_name) f where f.tablespace_name = a.tablespace_name and a.next_extent > f.big_chunk;
如果有记录返回,则表明这些对象的下一个扩展大于该对象所属表空间的最大扩展值,需调整相应表空间的存储参数。
3. 检查Oracle数据库备份结果
包含: a.检查数据库备份日志信息; b.检查backup卷中文件产生的时间; c.检查oracle用户的email
3.1 检查数据库备份日志信息
假设:备份的临时目录为/backup/hotbakup,我们需要检查2009年7月22日的备份结果,则用下面的命令来检查:
cat /backup/hotbackup/hotbackup-09-7-22.log|grep –i error
备份脚本的日志文件为hotbackup-月份-日期-年份.log,在备份的临时目录下面。如果文件中存在“ERROR:”,则表明备份没有成功,存在问题需要检查。
3.2 检查backup卷中文件产生的时间
ls –lt /backup/hotbackup
backup卷是备份的临时目录,查看输出结果中文件的日期,都应当是在当天凌晨由热备份脚本产生的。如果时间不对则表明热备份脚本没执行成功。
3.3 检查oracle用户的email
tail –n 300 /var/mail/oracle
热备份脚本是通过Oracle用户的cron去执行的。cron执行完后操作系统就会发一条Email通知Oracle用户任务已经完成。查看Oracle email中今天凌晨部分有无ORA-,Error,Failed等出错信息,如果有则表明备份不正常。
4.检查Oracle数据库性能
在本节主要检查Oracle数据库性能情况,包含:检查数据库的等待事件,检查死锁及处理,检查cpu、I/O、内存性能,查看是否有僵死进程,检查行链接/迁移,定期做统计分析,检查缓冲区命中率,检查共享池命中率,检查排序区,检查日志缓冲区,总共十个部分。
4.1 检查数据库的等待事件
set pages 80
set lines 120
col event for a40
select sid, event, p1, p2, p3, WAIT_TIME, SECONDS_IN_WAIT
from v$session_wait where event not like 'SQL%' and event not like 'rdbms%';
如果数据库长时间持续出现大量像latch free,enqueue,buffer busy waits,db file sequential read,db file scattered read等等待事件时,需要对其进行分析,可能存在问题的语句。
4.2 Disk Read最高的SQL语句的获取
SELECT SQL_TEXT FROM (SELECT * FROM V$SQLAREA ORDER BY DISK_READS) WHERE ROWNUM <= 5;
4.3 查找前十条性能差的sql
SELECT * FROM ( SELECT PARSING_USER_ID EXECUTIONS, SORTS, COMMAND_TYPE, DISK_READS, SQL_TEXT FROM V$SQLAREA ORDER BY DISK_READS DESC) WHERE ROWNUM < 10;
4.4 等待时间最多的5个系统等待事件的获取
SELECT * FROM (SELECT * FROM V$SYSTEM_EVENT WHERE EVENT NOT LIKE 'SQL%' ORDER BY TOTAL_WAITS DESC) WHERE ROWNUM <= 5;
4.5 检查运行很久的SQL
COLUMN USERNAME FORMAT A12
COLUMN OPNAME FORMAT A16
COLUMN PROGRESS FORMAT A8
SELECT USERNAME, SID, OPNAME,
ROUND(SOFAR * 100 / TOTALWORK, 0) || '%' AS PROGRESS,
TIME_REMAINING, SQL_TEXT FROM V$SESSION_LONGOPS, V$SQL
WHERE TIME_REMAINING <> 0 AND SQL_ADDRESS = ADDRESS AND SQL_HASH_VALUE = HASH_VALUE;
4.6 检查消耗CPU最高的进程
SET LINE 240
SET VERIFY OFF
COLUMN SID FORMAT 999
COLUMN PID FORMAT 999
COLUMN S_# FORMAT 999
COLUMN USERNAME FORMAT A9 HEADING "ORA USER"
COLUMN PROGRAM FORMAT A29
COLUMN SQL FORMAT A60
COLUMN OSNAME FORMAT A9 HEADING "OS USER"
SELECT P.PID PID, S.SID SID, P.SPID SPID,
S.USERNAME USERNAME, S.OSUSER OSNAME, P.SERIAL# S_#,
P.TERMINAL, P.PROGRAM PROGRAM, P.BACKGROUND, S.STATUS,
RTRIM(SUBSTR(A.SQL_TEXT, 1, 80)) SQL FROM V$PROCESS P,
V$SESSION S, V$SQLAREA A
WHERE P.ADDR = S.PADDR AND S.SQL_ADDRESS = A.ADDRESS(+) AND P.SPID LIKE '%&1%';
4.7 检查碎片程度高的表
SELECT segment_name table_name, COUNT(*) extents FROM dba_segments
WHERE owner NOT IN ('SYS', 'SYSTEM')
GROUP BY segment_name HAVING COUNT(*) = (SELECT MAX(COUNT(*))
FROM dba_segments GROUP BY segment_name);
4.8 检查表空间的I/O比例
SELECT DF.TABLESPACE_NAME NAME, DF.FILE_NAME "FILE", F.PHYRDS PYR, F.PHYBLKRD PBR, F.PHYWRTS PYW, F.PHYBLKWRT PBW FROM V$FILESTAT F, DBA_DATA_FILES DF WHERE F.FILE# = DF.FILE_ID ORDER BY DF.TABLESPACE_NAME;
4.9 检查文件系统的I/O比例
SELECT SUBSTR(A.FILE#, 1, 2) "#", SUBSTR(A.NAME, 1, 30) "NAME", A.STATUS, A.BYTES, B.PHYRDS, B.PHYWRTS FROM V$DATAFILE A, V$FILESTAT B WHERE A.FILE# = B.FILE#;
4.10 检查死锁及处理
查询目前锁对象信息:
select sid, serial#, username, SCHEMANAME, osuser, MACHINE, terminal, PROGRAM, owner, object_name, object_type, o.object_id from dba_objects o, v$locked_object l, v$session s where o.object_id = l.object_id and s.sid = l.session_id;
oracle级kill掉该session:
alter system kill session '&sid,&serial#';
操作系统级kill掉session:
>kill -9 pid
5. 检查数据库cpu、I/O、内存性能
记录数据库的cpu使用、IO、内存等使用情况,使用vmstat,iostat,sar,top等命令进行信息收集并检查这些信息,判断资源使用情况。
5.1 CPU使用情况:
sar 1 10
注意上面的蓝色字体部分,此部分内容表示系统剩余的cpu,当其平均值下降至10%以下的时视为CPU使用率异常,需记录下该数值,并将状态记为异常。
5.2 内存使用情况:
# free -m
total used free shared buffers cached
Mem: 2026 1958 67 0 76 1556-/+ buffers/
cache: 326 1700Swap: 5992 92 5900
如上所示,蓝色部分表示系统总内存,红色部分表示系统使用的内存,黄色部分表示系统剩余内存,当剩余内存低于总内存的10%时视为异常。
5.3 系统I/O情况:
# iostat -k 1 3
Linux 2.6.9-22.ELsmp (AS14) 07/29/2009
avg-cpu: %user %nice %sys%iowait %idle
0.16 0.00 0.05 0.36 99.43
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 3.33 13.16 50.25 94483478 360665804
avg-cpu: %user %nice %sys%
iowait %idle0.00 0.00 0.00 0.00 100.00
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.00 0.00 0.00 0 0
如上所示,蓝色字体部分表示磁盘读写情况,红色字体部分为cpu IO等待情况。
5.4 系统负载情况:
# uptime
12:08:37 up 162 days, 23:33, 15 users, load average: 0.01, 0.15, 0.10
如上所示,蓝体字部分表示系统负载,后面的3个数值如果有高于2.5的时候就表明系统在超负荷运转了,并将此值记录到巡检表,视为异常。
5.5 查看是否有僵死进程
select spid from v$process where addr not in (select paddr from v$session);
有些僵尸进程有阻塞其他业务的正常运行,定期杀掉僵尸进程。
5.6 检查行链接/迁移
select table_name, num_rows, chain_cnt From dba_tables Where owner = 'CTAIS2' And chain_cnt <> 0;
注:含有long raw列的表有行链接是正常的,找到迁移行保存到chained_rows表中,如没有该表执行../rdbms/admin/utlchain.sql
analyze table tablename list chained rows;
可通过表chained_rows中table_name,head_rowid看出哪些行是迁移行
create table aa as select a.* from sb_zsxx a,chained_rows b where a.rowid=b.head_rowid and b.table_name ='SB_ZSXX'; delete from sb_zsxx where rowid in (select head_rowid from chained_rows where table_name = 'SB_ZSXX');insert into sb_zsxx select * from chained_row where table_name = 'SB_ZSXX';
5.7 定期做统计分析
对于采用Oracle Cost-Based-Optimizer的系统,需要定期对数据对象的统计信息进行采集更新,使优化器可以根据准备的信息作出正确的explain plan。在以下情况更需要进行统计信息的更新: a. 应用发生变化 b. 大规模数据迁移、历史数据迁出、其他数据的导入等 c .数据量发生变化 查看表或索引的统计信息是否需更新,如:
Select table_name,num_rows,last_analyzed
From user_tables where table_name ='DJ_NSRXX'select count(*) from DJ_NSRXX
如num_rows和count(*)
如果行数相差很多,则该表需要更新统计信息,建议一周做一次统计信息收集,如:
exec sys.dbms_stats.gather_schema_stats(ownname=>'CTAIS2',cascade => TRUE,degree => 4);
5.8 检查缓冲区命中率
SELECT a.VALUE + b.VALUE logical_reads, c.VALUE phys_reads, round(100 * (1 - c.value / (a.value + b.value)), 4) hit_ratio FROM v$sysstat a, v$sysstat b, v$sysstat c WHERE a.NAME = 'db block gets' AND b.NAME = 'consistent gets' AND c.NAME = 'physical reads';
如果命中率低于90%则需加大数据库参数db_cache_size。
5.9 检查共享池命中率
select sum(pinhits) / sum(pins) * 100 from v$librarycache;
如低于95%,则需要调整应用程序使用绑定变量,或者调整数据库参数shared pool的大小。
5.10 检查排序区
select name,value from v$sysstat where name like '%sort%';
如果disk/(memoty+row)的比例过高,则需要调整sort_area_size(workarea_size_policy=false)或pga_aggregate_target(workarea_size_policy=true)。
5.11 检查日志缓冲区
select name,value from v$sysstat where name in ('redo entries','redo buffer allocation retries');如果redo buffer allocation retries/redo entries超过1%,则需要增大log_buffer。
6. 检查数据库安全性
在本节主要检查Oracle数据库的安全性,包含:检查系统安全信息,定期修改密码,总共两个部分。
6.1 检查系统安全日志信息
系统安全日志文件的目录在/var/log下,主要检查登录成功或失败的用户日志信息。
检查登录成功的日志:
grep -i accepted /var/log/secure
检查登录失败的日志:
grep -i inval /var/log/secure && grep -i failed /var/log/secure
在出现的日志信息中没有错误(Invalid、refused)提示,如果没有(Invalid、refused)视为系统正常,出现错误提示,应作出系统告警通知。
6.2 检查用户修改密码
在数据库系统上往往存在很多的用户,如:第三方数据库监控系统,初始安装数据库时的演示用户,管理员用户等等,这些用户的密码往往是写定的,被很多人知道,会被别有用心的人利用来攻击系统甚至进行修改数据。需要修改密码的用户包括: 数据库管理员用户SYS,SYSTEM;其他用户。 登陆系统后,提示符下输入cat /etc/passwd,在列出来的用户中查看是否存在已经不再使用的或是陌生的帐号。若存在,则记录为异常。
修改密码方法:
alter user USER_NAME identified by PASSWORD;
6.3 检查运行日志大小
进入运行日志目录,查看日志文件大小
du -h alert/
du -h trace/
如果日志文件过大,使用 rm 删除较早的文件。
6.4 检查监听日志大小
du -h alert/
du -h trace/
如果日志文件过大,使用 rm 删除较早的文件。
6.5 后台预警日志文件检查
tail -200 alert_*.log
查看预警日志,最近是否有数据库异常预警日志。
7. 其他检查
在本节主要检查当前crontab任务是否正常,检查Oracle Job是否有失败等共六个部分。
7.1 检查当前crontab任务是否正常
[oracle@AS14 ~]$ crontab -l
7.2 Oracle Job是否有失败
select job,what,last_date,next_date,failures,broken from dba_jobs Where schema_user='CAIKE';
如有问题建议重建job,如:
exec sys.dbms_job.remove(1); commit; exec sys.dbms_job.isubmit(1,'REFRESH_ALL_SNAPSHOT;',SYSDATE+1/1440,'SYSDATE+4/1440'); commit;
7.3 监控数据量的增长情况
select A.tablespace_name, (1 - (A.total) / B.total) * 100 used_percent from (select tablespace_name, sum(bytes) total from dba_free_space group by tablespace_name) A, (select tablespace_name, sum(bytes) total from dba_data_files group by tablespace_name) B where A.tablespace_name = B.tablespace_name;
根据本周每天的检查情况找到空间扩展很快的数据库对象,并采取相应的措施:
删除历史数据 移动规定数据库中至少保留6个月的历史数据,所以以前的历史数据可以考虑备份然后进行清除以便释放其所占的资源空间。
扩表空间
alter tablespace <tablespace_name> add datafile ‘<file>’ size <size> autoextend off;
注意:在数据库结构发生变化时,如增加了表空间,增加了数据文件或重做日志文件这些操作,都会造成Oracle数据库控制文件的变化,DBA应及进行控制文件的备份,备份方法是:
执行SQL语句:
alter database backup controlfile to '/home/backup/control.bak';
或:
alter database backup controlfile to trace;
这样,会在USER_DUMP_DEST(初始化参数文件中指定)目录下生成创建控制文件的SQL命令。
7.4 检查失效的索引
select index_name, table_name, tablespace_name, status From dba_indexes Where owner = 'CTAIS2' And status <> 'VALID';
注:分区表上的索引status为N/A是正常的,如有失效索引则对该索引做rebuild,如:
alter index INDEX_NAME rebuild tablespace TABLESPACE_NAME;
7.5 检查不起作用的约束
SELECT owner, constraint_name, table_name, constraint_type, status FROM dba_constraints WHERE status = 'DISABLE' and constraint_type = 'P';
如有失效约束则启用,如:
alter Table TABLE_NAME Enable Constraints CONSTRAINT_NAME;
7.6 检查无效的trigger
SELECT owner, trigger_name, table_name, status FROM dba_triggers WHERE status = 'DISABLED';
如有失效触发器则启用,如:
alter Trigger TRIGGER_NAME Enable;
8.检查物理设备
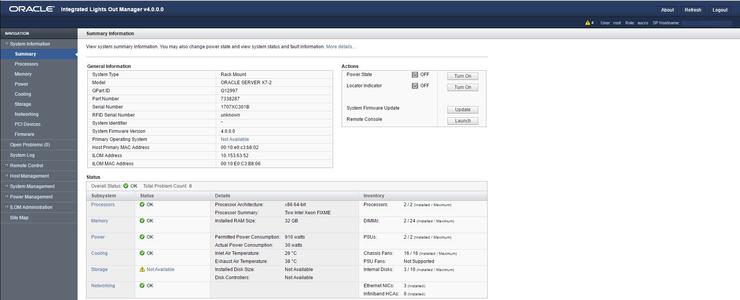
8.1 检查主机硬件状态
使用 https:// Web方式登陆所有物理节点 ILOM控制台(缺省:root/***)
检查主机CPU、内存、电源、等硬件状
8.2 物理磁盘查看
查看有多少asm磁盘
kfod disk=all
查看asm磁盘组
kfod op=groups
查看磁盘与磁盘组的对应关系
kfod ds=true di=all
9. ASM 共享磁盘查看
9.1 查看磁盘路径
select name, path, group_number from v$asm_disk_stat;
9.2 查看磁盘组信息
select state,name,type,total_mb, free_mb from v$asm_diskgroup_stat;
9.3 查看磁盘组操作
select * from v$asm_operation;
9.4 查看磁盘组属性
查询V$ASM_ATTRIBUTE视图查看磁盘组属性
SELECT dg.name AS diskgroup,SUBSTR(a.name,1,18) AS name,SUBSTR(a.value,1,24) AS value, read_only FROM V$ASM_DISKGROUP_STAT dg, V$ASM_ATTRIBUTE a WHERE dg.name = 'DATA' AND dg.group_number = a.group_number;
9.5 查看磁盘组兼容属性
SELECT name,COMPATIBILITY,DATABASE_COMPATIBILITY FROM V$ASM_DISKGROUP_STAT;
9.6 查看磁盘状态
SELECT SUBSTR(d.name,1,16) AS asmdisk,d.mount_status,HEADER_STATUS, d.state, dg.name AS diskgroup FROM V$ASM_DISKGROUP_STAT dg, V$ASM_DISK_STAT d WHERE dg.group_number = d.group_number;
9.7 查看磁盘客户端信息
SELECT dg.name AS diskgroup,SUBSTR(c.instance_name,1,12) AS instance, SUBSTR(c.db_name,1,12) AS dbname,SUBSTR(c.SOFTWARE_VERSION,1,12) AS software, SUBSTR(c.COMPATIBLE_VERSION,1,12) AS compatible FROM V$ASM_DISKGROUP_STAT dg, V$ASM_CLIENT c WHERE dg.group_number = c.group_number;
9.8 查看磁盘访问控制用户信息
SELECT dg.name AS diskgroup, u.group_number,u.user_number, u.os_id, u.os_name FROM V$ASM_DISKGROUP_STAT dg, V$ASM_USER u WHERE dg.group_number = u.group_number AND dg.name ='DATA';
9.9 查看磁盘访问控制组信息
SELECT dg.name AS diskgroup, ug.group_number,ug.owner_number, u.os_name, ug.usergroup_number, ug.name FROM V$ASM_DISKGROUP_STAT dg, V$ASM_USER u, V$ASM_USERGROUP ug WHERE dg.group_number = ug.group_number AND dg.name ='DATA' AND ug.owner_number = u.user_number;
9.10 查看智能数据分布信息
SELECT dg.name AS diskgroup, f.file_number, f.primary_region, f.mirror_region, f.hot_reads,f.hot_writes, f.cold_reads, f.cold_writes FROM V$ASM_DISKGROUP_STAT dg, V$ASM_FILE f WHERE dg.group_number = f.group_number and dg.name ='DATA';
10. 集群状态
10.1 检查数据库集群状态是否正常
crs_stat -t
10.2 列出数据库
srvctl config database
10.3 列出数据库的实例
srvctl status database -d orcl
10.4 数据库的配置
srvctl config database -d orcl -a
10.5 集群名称
cemutlo -n
10.6 检查集群栈状态
crsctl check cluster -all
10.7 集群的资源
crsctl status res -t
每个节点的更加详细的资源
crsctl status res -t -init
10.8 检查节点应用
srvctl status nodeapps
10.9 检查SCAN
检查scan-ip地址的配置
srvctl config scan
检查scan-ip地址的实际分布及状态
srvctl status scan
检查scan监听配置
srvctl config scan_listener
检查scan监听状态
srvctl status scan_listener
10.10 检查VIP和监听
# 检查VIP的配置情况
srvctl config vip -n node1
srvctl config vip -n node2
# 检查VIP的状态
srvctl status nodeapps
# 或
srvctl status vip -n node1
srvctl status vip -n node2
# 检查本地监听配置:
srvctl config listener -a
# 检查本地监听状态:
srvctl status listener
10.11 检查ASM
# 检查ASM状态
srvctl status asm -a
# 检查ASM配置
srvctl config asm -a
# 检查磁盘组
srvctl status diskgroup -g DATA
# 查看ASM磁盘
oracleasm listdisks
10.12 检查集群节点间的时钟同步
检查节点node1的时间同步